批发
批发 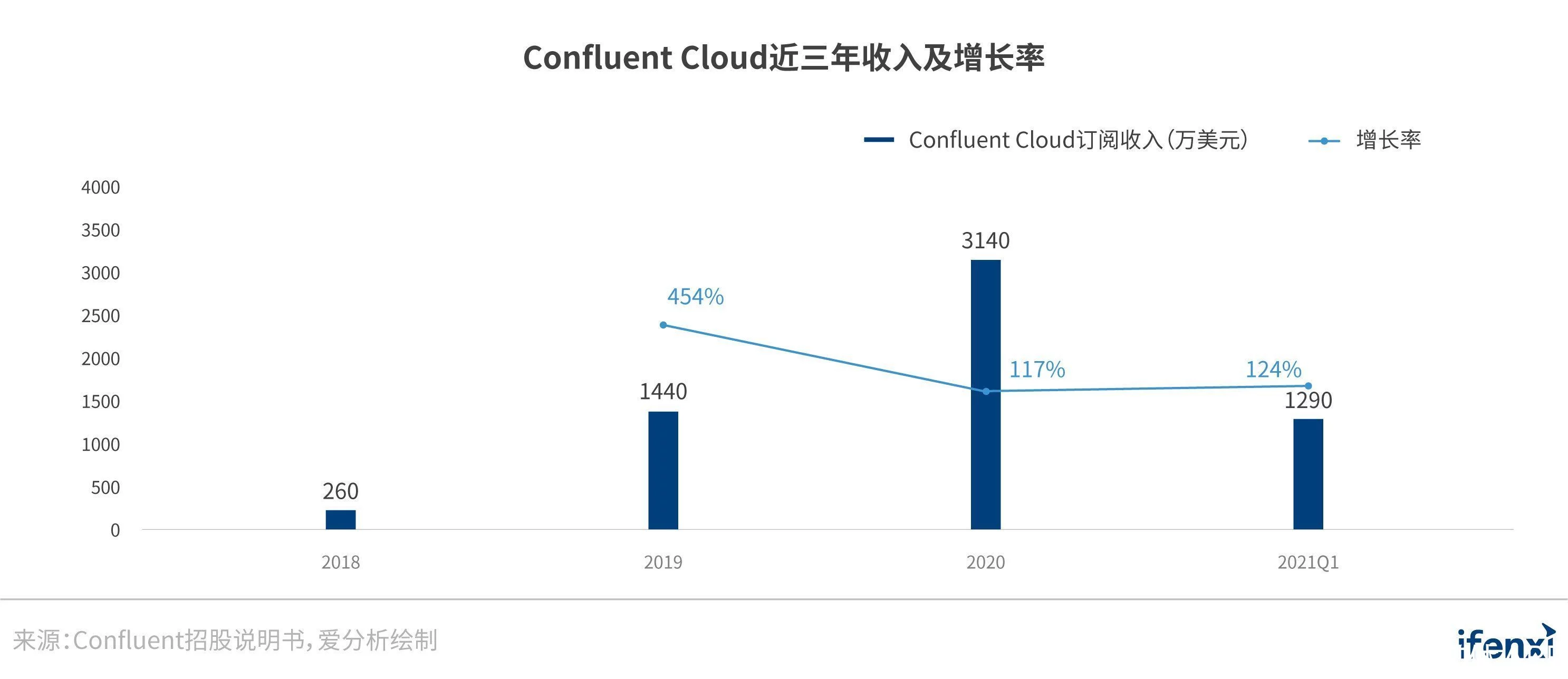
咨询微信:TGBY2021

和奢侈品代工厂出自同一厂家,和专柜无区别。我们拥有深厚的专业基础,严格质量管理制度、坚持一流的品质保证。赢得广大消费者的信赖。本着互惠互利的原则,愿与广大客商携手并进、共创辉煌!
我们位于广州高仿名表市场,主要信息介绍:高仿名表价格、高仿名牌手表商品图片,我们这里全是精仿名表,价格在380到680之间,布料和面料和专柜一样品质,你说和专柜有什么不一样呢!
就是心理问题吧,我们自家工厂已有近十年的做货经验,专门聘请曾经在国内大牌手表代工厂工作多年的老师傅,经验丰富,在高仿大牌手表的做工,机芯制造以及外形款式上与正品保持高度一致。我们在国内高仿手表市场屹立多年,自家工厂做高仿大牌手表的技术经历了千锤百炼,在款型,手感上已经与正品相差无几。或许在皮质用料上与正品不同,但谁说正品的布料就一定是最好的,只要机芯走时无误差,五金光泽好看,做工精湛,就是好手表。
我们的优势: 【货源 】 我们团队拥有一手货源。直接拿出厂价,不需要囤货,可一件代发。这完全属于零创业。 【人脉】 我们团队拥有独家的人脉,引流方案,你无需担心人脉问题。你不需要去寻找任何加好友的方法,只需要别人来加你就好。并且,一般找上来的90%都是精准粉,不是代理,就是加盟或者零售,而这三方面无论是哪一方,都是你赚钱的平台。
【模式】 我们的货源是一种新型的模式,有三大好处: 1.不用囤货,不用压货,零风险。 2.我们团队不分123大小,你能赚多少钱就能得多少钱,并且都是厂家加出售。利润空间自己掌握,挣得钱不需要和任何人分享。 3.现在做的是引流模式,不是之前的刷屏模式。
在数仓时代,企业的数据分析需求以处理结构化数据、为业务人员作报表应用为主,MPP架构在当时能够很好地满足这些需求。
但随着互联网、移动互联网的逐步普及,企业内沉淀的数据量呈现出爆发式增长,不仅数据量本身变得很大,数据类型也从原来的结构化数据为主,发展为包含各类结构化、半结构化、非结构化,以及图片和音视频数据。MPP架构无法承接对大量非结构化和半结构化数据的处理,而Hadoop架构由于生态内具有众多组件能够实现不同功能,可以处理复杂类型的数据,其分布式架构也能够为企业实现大数据分析的高性能,以Hadoop为基础的数据湖架构兴起。
然而近年来,企业面临的数据分析业务需求也发生了重要改变,使得Hadoop越来越不能很好地满足企业日益复杂的分析需求。这些改变主要体现在三个方面:
1)随着数字化转型浪潮的推进,企业有越来越多在线化、互联网化的业务场景,上云的渗透率越来越高,大量数据的产生、采集和应用都发生在云端,而更适应本地化部署特性的Hadoop很难满足企业数据流动的需要。
2)同样随着企业数字化的深入,企业产生了大量创新性的数据应用需求,需要快速落地、快速迭代。而Hadoop架构由于过于繁重,无法适应企业对数据应用的敏捷性需求。
3)人工智能和机器学习在数据分析领域的应用正在加速落地,而一些高级的分析框架,比如TensorFlow,其分布式架构在设计之初就是基于云原生架构,没有考虑过Hadoop架构,因此在Hadoop上很难部署和运行这类高级分析框架。
02 云原生架构的浪潮已经到来既然Hadoop在面对新的数据分析需求时已经展现出种种不足,那下一代架构是什么?事实上,包括Confluent在内的新一代大数据公司已经回答了这个问题——拥抱云原生。云原生是指在应用的设计阶段就为了云的运行环境而设计,包含微服务、容器化、DevOps、持续交付等特征,充分利用和发挥云平台的弹性和分布式架构的优势。
由于意识到企业用户的需求正在往云端、存储计算分离、敏捷等方向上发展,一些领先的大数据公司早在几年前就将重点放在了云原生版本的产品上,也由此获得了显著的成功。
以刚刚IPO的Confluent公司为例,其所代表的开源流数据工具Kafka最早也是源自于Hadoop生态。Kafka为不同数据源之间数据的交换这个任务而生,Confluent将Kafka商业化推出Confluent Platform并取得了成功,随后在2018年推出了云原生的版本Confluent Cloud,为用户提供完全托管的云端服务,具备弹性伸缩以及支持用户敏捷开发等特性。
根据Confluent招股说明书,Confluent Cloud在2020年取得了3140万美元的订阅收入,2019年、2020年和2021年前3个月的增速分别达到454%、117%和124%。尽管Confluent Cloud的收入目前仅占到公司总收入的20%左右,但其表现出的成长性远超本地产品Confluent Platform约50%的增速。Confluent在招股说明书中也强调了公司云原生的战略,并将Confluent Cloud视为公司未来收入增长的最重要产品。这应该也是资本市场给与Confluent高度认可的主要原因。
在此之前,去年IPO、市值曾达800亿美元的明星大数据公司Snowflake,更是云原生的代表。Snowflake针对云计算环境将产品特性进行了深度优化,在云端向客户提供简单易用、弹性伸缩、按使用量计费的一站式数据管理和分析平台。其突出特征是支持计算、存储节点单独扩展,从而实现了资源的精细化管理,有效降低了扩容成本,同时可以做到按使用量付费。
同样是硅谷热门的大数据公司Databricks,其提供的是一个云上的面向数据分析师和数据科学家的大数据分析平台,用户可以通过Databricks在云端环境中实施整个大数据方案,从数据提取、数据转换、交互式处理,到数据产品等。Databricks底层计算使用Spark,存储使用Delta云存储服务,支撑了企业在云端对各种结构化、半结构化和非结构化数据的分析。
联系微信:TGBY2021 QQ号:1053547598 加我时注明在【第一货源网】看到的,有优惠哦。